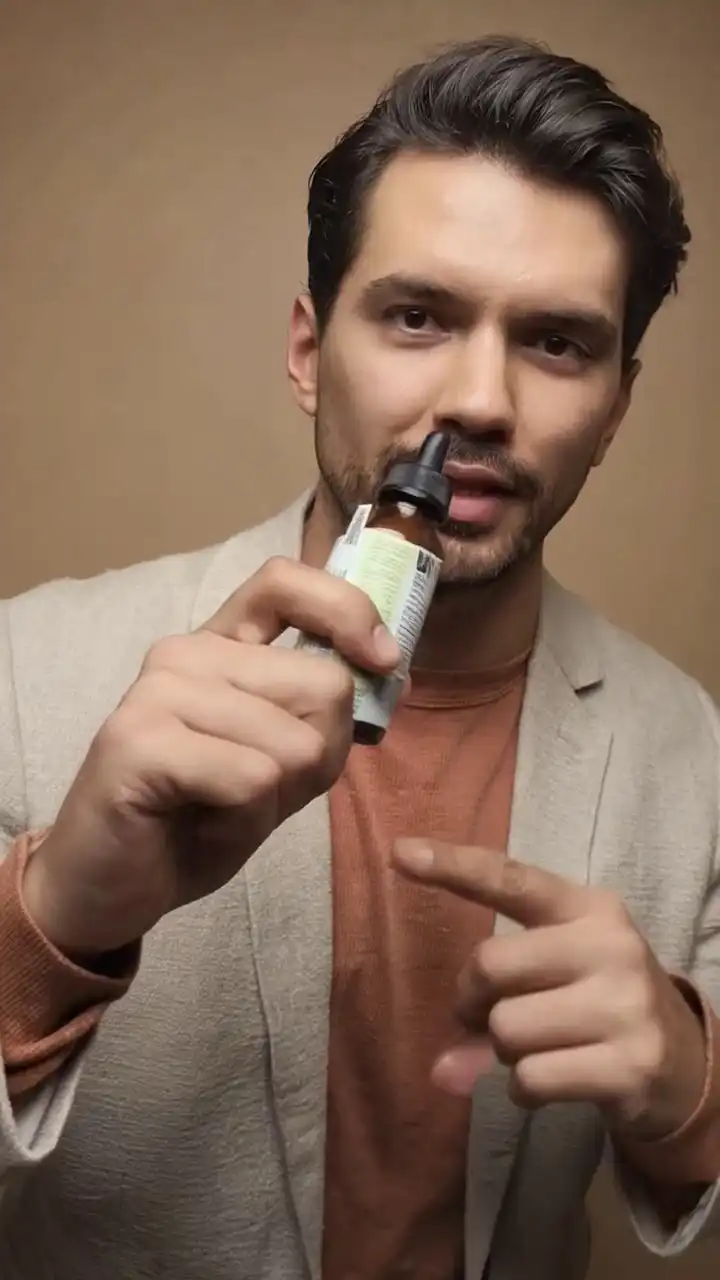

01R2V
Reference-to-Video (R2V) — AI Product Video from Photos
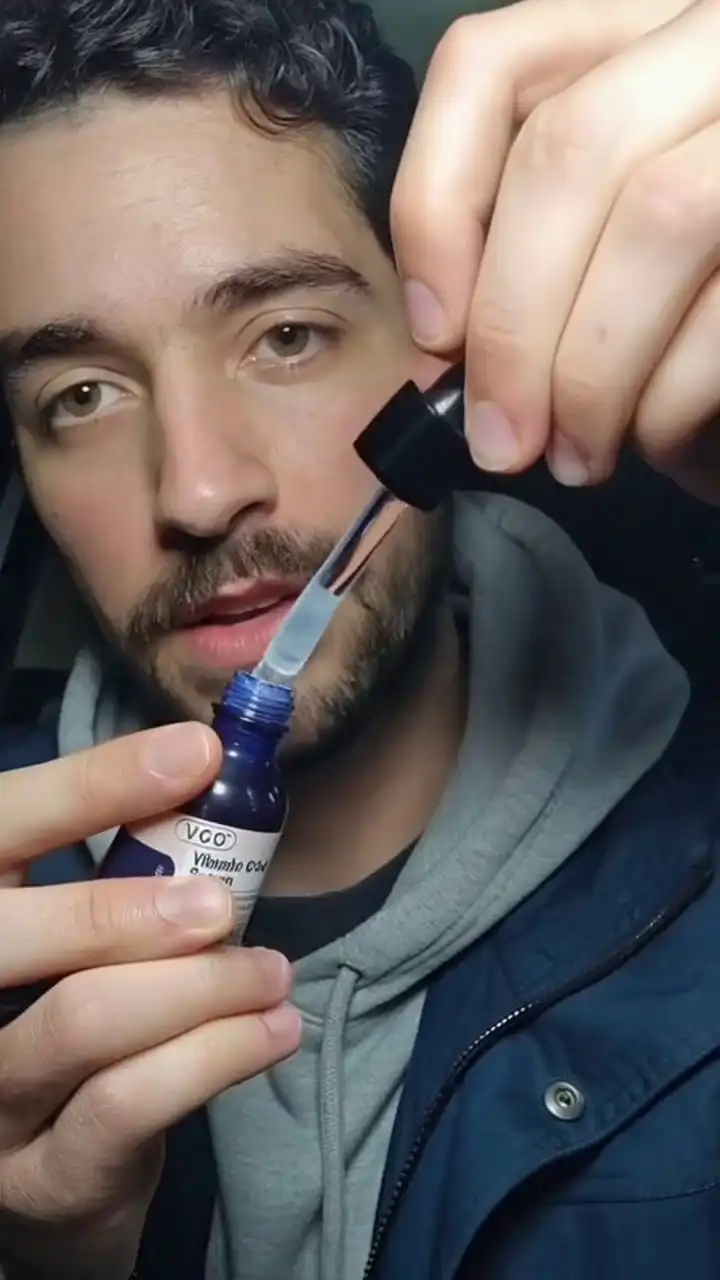
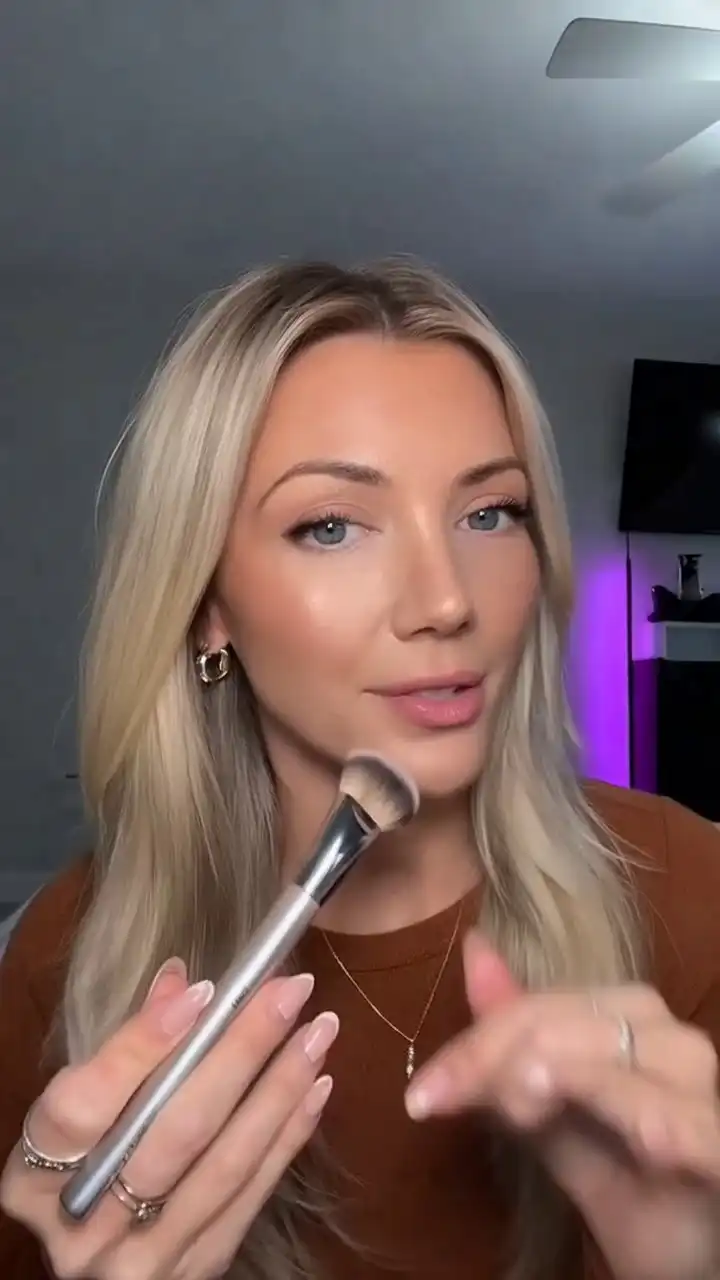
Upload a product photo and a model reference image. OmniShow holds color, texture, and shape consistent across every frame — no drift, no distortion, no 3D setup.
- Inputs
- Text prompt · product photo · model reference
- Output
- Product demo video with natural hand-object contact.
“The young woman with long, wavy dark red hair is holding a sleek black and rose gold hairdryer in a softly lit indoor setting. The hairdryer is regular-size, designed for comfortable handling and efficient drying. She is speaking directly to the camera, demonstrating the features of the hairdryer with expressive hand gestures, including pointing to the buttons on the handle as she explains its functions.”
 Product
Product Model
ModelTextReference Images